흐름정리
- DB
파일시스템 : 논리적 파일구조와 물리적 파일구조 간에 일대일로 사상되며 동시 공유,보안,회복 기능이 부족함
따라서 DBMS는 모든 응용프로그램이 DB를 공유 엑세스 할수 있도록 여러 제어 접근 관리를 수행하는 소프트웨어이다

- 기본키,후보키 : 유일성과 최소성을 갖는 모든 것
- 대체키 : 후보키중에서 기본키를 제외한 것
- 외래키 : 외래키는 참조 릴레이션의 기본키와 동일해야 하며 null이 올수 없다.
- 슈퍼키 : 유일성은 만족하지만 최소성은 만족하지 않는다.
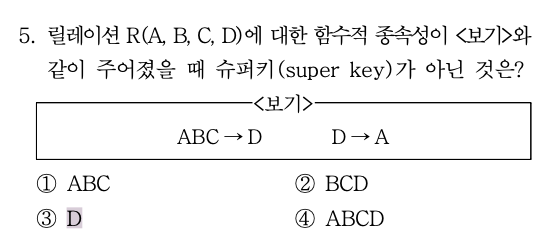
핵심은 각 보기의 키를 알면 모든 키가 결정이 되는가? D는 알아도 나머지 결정에는 부족하다. + 최소성은 만족안해도 됨
- 개체 무결성 : 기본키는 null이 안되며 중복될수 없다.
- 참조 무결성 : 외래키 값은 참조릴레이션의 기본키와 같아야 한다. 즉 참조하려면 존재해야한다
- 키 무결성 : 한 릴레이션에는 최소한 하나의 키가 존재해야 한다.
데이터베이스를 관점을 기준으로 3단계로 구분한다
외부 - 개념 - 내부 스키마 존재
(논리적) (물리적) 독립성
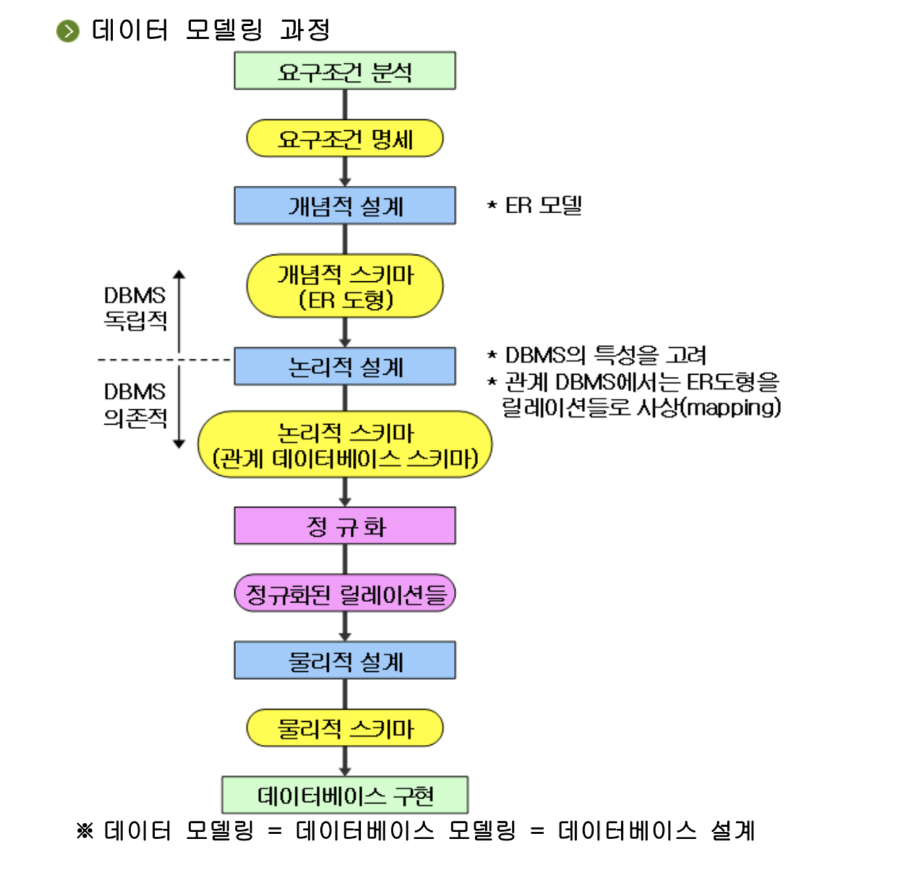
개념적 설계 : 트렌잭션 모델링, 요구사항 토대로 ER다이어그램만듬
논리적 설계 : 트랜잭션 인터페이스 설계, 스키마의 평가 및 정제
물리적 설계 : 저장 레코드 양식 설계, 접근 경로, 파일의 저장 구조 및 탐색 기법,인덱스..
- 논리적,물리적 데이터 독립성
논리적 데이터 독립성은 외부스키마와 개념스키마 사이의 사상에 의해 제공된다.
응용 프로그램 영향 주지 않고 데이터베이스 논리적 구조 수정 가능
물리적 데이터 독립성은 응용프로그램의 변경없이 성능 향상을 위한 파일의 접근구조를 수정할 수 있게 한다.
- 데이터베이스 설계의 주요 단계
요구사항 수집 및 분석 - 개념적 설계 - 논리적 설계 - 정규화 - 물리적 설계 - 데이터베이스 튜닝
데이터 언어는 DDL(create,alter,drop),DML(select,insert,update,delete),DCL로 구분
DBMS 위에는 응용프로그램들이 있고 안에는 DDL,DML컴파일러, 질의어 처리기 등이 있다.
밑에는 시스템 카탈로그가 있다. 여기에 스키마 정보나 데이터 개체 정의 명세 관리
Cardinality : 튜플 개수
Degree : 속성 개수
관계 데이터 모델
관계 대수(절차적)
집합,조인.. 등등
- 외부 조인(outer join)
왼쪽 외부 조인 : 왼쪽 테이블의 모든 데이터(칼럼)를 포함하는 결과가 생성된다.
전체 외부 조인 : 왼,오 테이블 모든 데이터(칼럼)을 포함하는 결과가 생성
- 내부 조인(inner join) = 자연조인
두 테이블에서 동일한 칼럼의 데이터가 일치하는 내용만 출력
- 세미조인
자연조인 한후에 한쪽 차수만 다 포함해서 나타나는 것이다
왼쪽으로 닫혀있으면 왼쪽거 포함 오른쪽으로 닫혀있으면 오른쪽 포함
관계 해석
입실론, 크고 작고 이런거
- 뷰
사용자들의 데이터 접근을 제어하여 보안성 높임
뷰 생성은 읽기전용과 갱신 가능(기본키가 포함되어 있을때) 상태로 정의할 수 있다.
뷰 메커니즘은 논리적 데이터 독립성을 지님
grant selet 를 부여 했을때 검색용 뷰를 생성할 순 있다 !
그 테이블의 키를 외래키로 참조하는 다른 테이블은 생성 할수 없다(ref 권한필요)
뷰 동치 : 3가지 조건 만족 1. 초기 읽기( 두스케쥴이 초기 읽기가 같아야함) 2. 쓰기/읽기 같아야함 3. 최종쓰기가 같아야함
- SQL
1. RESTRICT : 개체를 변경/삭제할 때 다른 개체가 변경/삭제할 개체를 참조하고 있을 경우 변경/삭제가 취소됩니다.(제한)
no action이랑 동일하게 해석할수 있음
2. CASCADE : 개체를 변경/삭제할 때 다른 개체가 변경/삭제할 개체를 참조하고 있을 경우 함께 변경/삭제됩니다.

: 여기서 2번은 열이 아니라 행을 삭제하는 것이다.

트리거 : 데이터의 무결성을 위해 명시된 이벤트가 발생할떄마다 DBMS가 자동적으로 수행하는 것
-> 행수준(for each row), 문장수준(for each statement)이 있다
assertion : 제약조건을 위반하는 연산이 수행되지 않도록 하는 것
- 키 특성에서 unique 랑 primary key는 특징이 거의 동일하다고 봐야함
- ANY는 어느 하나보다 크면됨 젤 작은거 빼게된다. OR의 느낌이 강하다
where은 group 전에 적용됨 group에 대해서는 having이 후에 적용
그리고 where절에서 집계함수 사용 불가능
SQL에서 where문 조건이 여러개 테이블에 대해서이고 그것들에 대해 select * from 어느 한 테이블 이렇게 해도
wher문에 조건들 따라서 다 join되서 나타난다.
내장sql은 개발자가 sql을 호스트 언어에 포함시켜서 실행하는 원리이다.
SQL앞에는 명령문의 구분을 위해 exec sql을 앞에 붙인다.(j까지)
- NoSql은 관계형 db보다 덜 일관적이다.
기존의 관계형 데이터베이스 시스템의 주요 특성을 보장하는 ACID(Atomic, Consistency, Integrity, Duarabity) 특성을 제공하지 않는, 그렇지만 뛰어난 확장성이나 성능 등의 특성을 갖는 수많은 비관계형, 분산 데이터 베이스들이 등장했고 NoSQL이라는 용어가 보편적으로 사용되었습니다.
NoSQL이 등장한 이후에도 시장에서는 관계형 데이터베이스가 데이터를 처리하는데 가장 최적의 시스템으로 받아들이고 있었습니다.
특히 기업의 ERP나, MIS 시스템 등 데이터의 정확한 처리가 필수적인 시스템에서는 현재도 관계형 데이터베이스를 사용하고 있습니다. 또한 무엇보다도 SQL 이라고 하는 데이터를 처리하는 언어의 편이성 때문에 NoSQL 등 다른 데이터베이스 시스템들은 많이 활용 되지 않고 있었습니다.
그러나, 2000년 후반으로 넘어오면서 인터넷이 활성화되고, 소셜네트워크 서비스 등이 등장하면서 관계형 데이터 또는 정형데이터가 아닌 데이터, 즉 비정형데이터라는 것을 보다 쉽게 담아서 저장하고 처리할 수 있는 구조를 가진 데이터 베이스들이 관심을 받게 되었고, 해당 기술이 점점 더 발전하게 되면서, NoSQL 데이터베이스가 각광을 받게 된 것입니다.
이제 전반적인 DBMS와 관계형 DB 사용을 알았으면 DB설계와 데이터 모델링을 해야함
설계과정은 요구조건 분석 - 개념적 설계 - 논리적 설계 - 물리적 설계
데이터모델링은 E-R모델을 사용
E-R(=개체 관계 모델) 다이어그램
이중선 = 전체참여, 무조건 튜플이 있어야 한다 ? 라는 의미인거 같다
부분참여는 반드시는 아니다 일부만 참여해도 됨( 0개이상의 의미 )
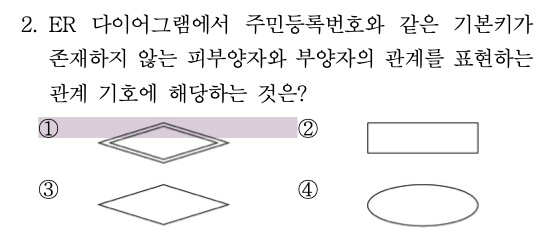
->사원의 키가 주민등록번호이고 그 사원의 부양자가 1,2,3,4이렇게 인덱스로 나와 있으면
그건 부분키로 나타내는데 1번으로 표현함
다대다(M N )관계에서는 이어주는 릴레이션 존재해야함
서브 타입 개체는 슈퍼 타입 개체로부터 속성은 물론 관계도 상속 받는다
다중값 속성(이중원), 재귀적 관계도 표현 가능함 , 확장하면 일반화 상속등이 추가됨
- 정규형 구분하기
1정규형 : 속성 값이 atomic해야함
2정규형 : 어떤 후보키에 부분함수 종속되면 안됨
3정규형 : 함수의 이행 종속이면 안됨
bycd : 키는 슈퍼키여야함 -> 이게 4정규형은 아니다. 그건 따로있음
4정규형은 BCNF + 다치종속성 만족해야한다.
모든건 키를 기준으로 봐야한다 a->b에서 a를 기준으로 판단해야함
1정규형은 속성값에 1,2이렇게 두개 들어가면 안된다는것
2정규형은 a,b -> c,d 이렇게 되있는데 알고보니 a,b->c 이고 b->d 이런식으로 부분적으로 종속이 되면 안된다는 것
3정규형은 a->c이렇게 되있는데 알고보니 a->e, e-> c이런것이면 안된다는 것이다.
정규화의 단점은 다시 조인할때 시간 오래 걸린다. 따라서 불필요한 분해는 하지 않는 것이 좋다. 만약 많이 분해 했을때 다시 이전 정규형으로 돌아오는게 역정규화이다. 오히려 질의 시간이 빨라질수 있다.
반정규화란 시스템의 성능향상, 개발 및 운영의 편의성을 위해 정규화된 데이터 모델을 통합, 중복 분리하는 과정으로 의도적으로 정규화 위반, 데이터의 일관성이 떨어질수도 있다.
api보안 : 부하 별로 발생x, 암복호화 빠르다, 그러나 프로그램에서의 수정은 필요
플러그인 :자체에 설치,독립성, 관리 편리
인덱싱 : 테이블 동작 속도를 높여주는 자료구조, 주로 b-tree를 사용
비트맵 인덱스는 인덱스 값을 0과 1로 변환하여 저장하는 것
5명 있으면 비트 5개 필요하고 해당하는걸 1로 표시함
해싱 :
- 데이터 값의 종류가 적고 동일한 데이터가 많을 경우에 많이 사용하는 인덱스
- B-Tree 인덱스는 데이터의 값의 종류가 많고 데이터가 적을 경우에 사용하는 인덱스
- 학생이 2천명이라 하더라도 성별 컬럼의 종류는 남,여 2가지뿐이므로 이곳은 BITMAP INDEX가 적당하다
- 학번 컬럼의 경우에는 B-TREE INDEX로 생성하는 것이 유리



- 질의어 처리
최적화 하기 위해 select 먼저 하는 등 규칙 존재
- 데이터 회복, 크게 세가지 로그 기반, 체크포인트 기법 , 그림자 페이지
로그 기반, (이거 책한번 봐야할듯 )
redo순서는 그냥 앞에서 부터 한다 (check point부터 이후 부터 아니라 처음부터)
1) 지연 갱신 기법 : 회복시 redo함, redo 단계에서 redo연산에 따른 레코드를 로그에 다시기록하진 않는다.
왜? 트랜잭션 commit전까지 갱신 내용 디스크에 저장하지 않고 지연하기 때문에 오류가 나도 갱신안해서 undo할 필요 없다.
commit이 로그에 정상적으로 적혀 있어도 디스크에 저장되지 않았을 경우에 대비해 redo만 하면 된다.
2) 즉시갱신 기법 : 회복시 undo함
왜? 트랜잭션이 계속 저장하기 때문에 오류 생기면 undo해야하는 듯 그리고 commit한 것도 다시 redo
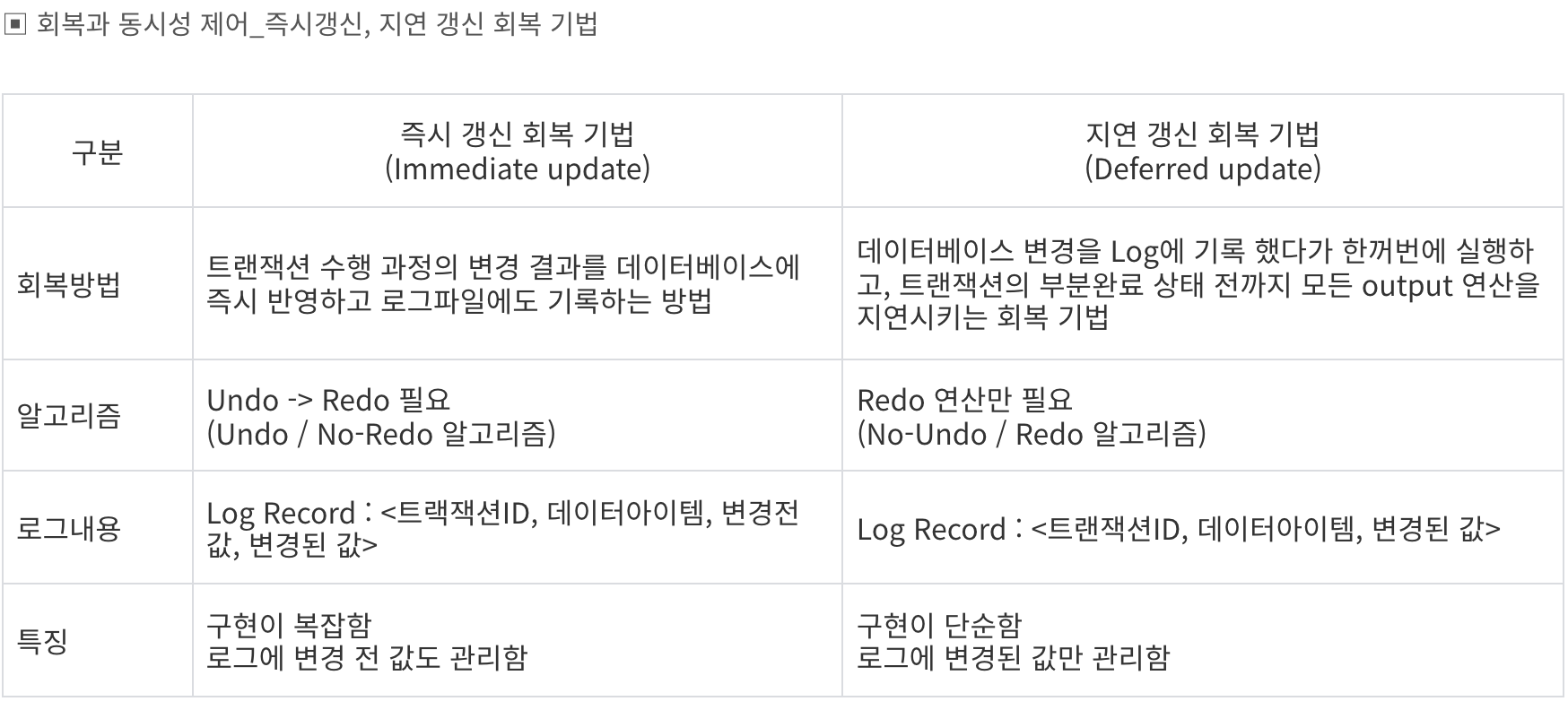
3) 체크포인터 기법 : 체크포인터 이전에 완료된건 무시, 이후에 대해서 완료된건 redo 완료 안되는건 undo함
체크포인트 이전것도 뒤에 commit안됫으면 undo해야함
4)그림자페이지 : 트랜잭션 완료시 갱신시켜줘야 함
checkpoint 회복 기법을 수행하기 위한 작업순서
- 로그 버퍼에 있는 모든 레코드를 안정된 저장소로 출력한다.
- 변경된 데이터 블록을 모두 안정된 저장소로 출력한다.
- 검사점 로그 레코드를 안정된 저장소로 출력한다.
- 로킹 기법 : 병행 제어 기법,로킹 단위 작을수록(속성) 병행성 증가
2단계 로킹 규약 : 확장 단계( 새로운 lock연산만 수행할 수 있다. unlock연산은 수행 불가)
축소단계 (unlock을 실행하면 lock연산은 실행할 수 없는 단계)
- 비연쇄 = 연쇄복귀가 없다는 것
- 오손판독 : 미완료된 트랜잭션이 쓴 것을 읽는 것 => 이때 연쇄복귀를 해야함
이것이 아니라면 비연쇄 스케쥴이라고 보면됨
- 유령데이터 읽기 : 한번 읽을땐 없었는데 두번쨰 읽을때 데이터가 들어옴
- 직렬 가능 스케줄 볼때
w가 일어난다음에 r가 일어나야함 아니면 갱신 분실 문제
ex> transaction 1 이 쓰기를 하면 그 이전에 작업하던 애들은 읽기를 한 후에 쓰기를 해야함 , 이전에 없었던 애들이 읽는건 고려할건 아니다.
ex> r1(x) r3(x) w1(x) r2(x) w3(x)
는 안됨 w1가 썻으면 r3가 읽어야됨 r2가 읽은건 상관 ㄴ 근데 w3가 읽엇으니 안됨
이런거 혹은 타임스탬프 기법 사용
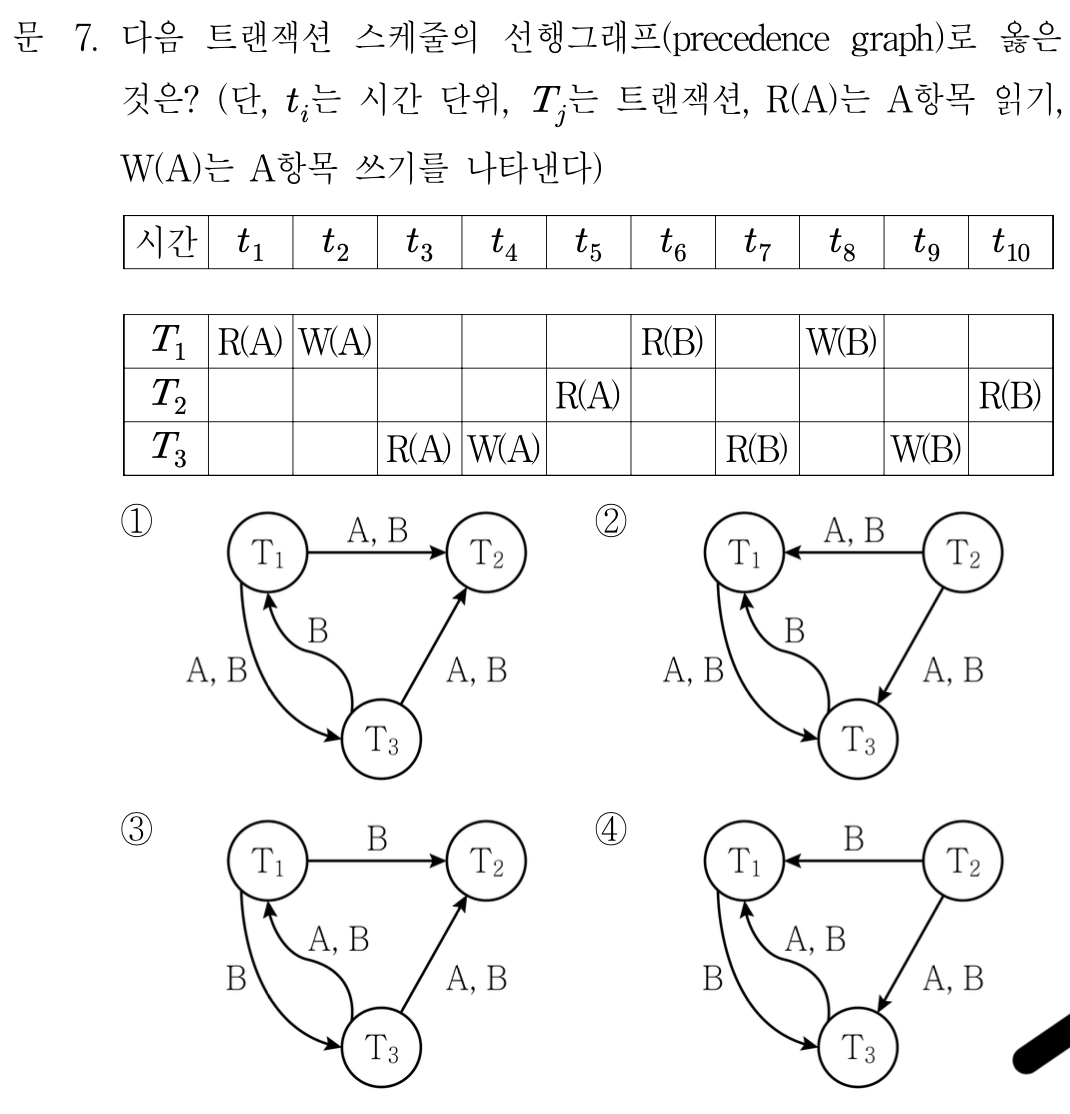
W하고나서 R한걸 기준으로 화살표가 간다 T2는 W한게 하나도 없으니 그을게 없다.
DBMS 3층 클라이어트 서버 구조
클라이언트 : gui
응용서버 : db서버 데이터 접근 하는 사용되는 비즈니스 규칙과 데이터 논리 처리
db서버 : 자료의 접근을 위한 dbms소프트웨어와 관련 데이터베이스를 가지고 있다.
시스템 카탈로그
dbms를 이용할때 복잡한 내부저장방식과 조직 전체의 정보구조 알필요 없이 요청만 할수 있게 해주는 것
사용자는 검색할수 있으며 안에 있는 데이터를 메타 데이터라고 함
- 데이터웨어하우스(read-only)
OLAP(On-line Analytical Processing)를 위한 시스템
OLAP 는 데이터 분석이나 의사결정을 지원하는 것을 지칭한다. 연산의 종류 : Roll up, Slicing/Dicing, Drill Down, Pivoting
스타 스키마를 사용하는데 이는 사실 테이블 + 차원 테이블로 구성된다.
사실테이블이 차원테이블을 참조하는 외래키를 가진다.
웨어하우스에 저장되는 데이터는 소스 데이터에 대한 실체화뷰로 간주될 수 있다.
- 질의최적화 :
주로 경험적 질의 최적화가 나온다.
규칙 기반 :
비용 기반 : 모든건 비교 못하고 다양한거 생성해서 비교
- 트랜잭션의 ACID = 원자성, 일관성, 고립성, 지속성
- db 데이터 보안을 제공하기 위한 4가지 주요 통제 수단
:접근제어, 흐름제어, 데이터 암호화, 추론제어

같은거만 출력
- 무결성 제약조건
Foreign key칼럼은 null 값을 가질 수 있다.
확장 e-r 모델에서 분리 제약조건과 완전성 제약조건
분리 : 개체가 오직 하나의 하위 단계 개체 집합에 속한다
중첩 : 개체가 하나 이상 하위 단계 개체 집합에 속할수 있다.
전체 : 개체는 어느 하나던 반드시 속해야함
부분 : 어느 하나에 반드시 속할 필요는 없다.
오답 : 2019년 9번(문제길어서 생략)

s2는 t1이 write한거에 t2가 읽고 쓰는데 t1이 abort해버려서 문제다.
s3에서 t2는 t1이 write 햇음에도 이를 읽지않고 x를 쓴다. 그래서 문제가 있지 않나 생각했는데 회복 가능하냐 불가능하냐로만 봣을때는 가능하다고 본다.
이런건 쭉 나열 해놓고 뒤에서부터 순서대로 하나씩 취소시켜보면서 취소시켰을때 다른 트랜잭션이 회복하는데 지장을 주면 회복 불가능이다.

a와 b가 다결정한다. 문제는 d->c이다. 이게 키가 아닌데 한 릴레이션안에 들어가면 부분종속이 생긴다.
따라서 이걸 다른 릴레이션에 키로서 만들어야 되고 3,4번이 남는다. 근데 d-> c이므로 3번이다. 저렇게 나누면 a-> c로 찾아가는건 사라진다고 보면됨

베타로크는 한놈이 걸면 다른놈은 못건다. 기다려야함
한명이 공유로크 건상태다? 그래도 못건다
공유로크는 누가 공유로크 걸어놔도 같이 공유해서 걸수 있다.
하지만 공유로크 걸어놧을때 베타 로크는 걸수 없다. 이런 특성때문에 서로 기다리는 교착상태에 빠질수도 있다.
이는 동시성제어를 하기 위해서이다. 왜하는가? 연쇄 복귀와 갱신분실을 막기 위해서이다.
잠금을 통해 동시성 제어가 되고 직렬가능하게 된다.
하지만 잘못 걸면 교착상태에 빠질수도 있다.
=>


- 직렬(Serial) 스케줄 : 트랜잭션 별로 연산을 순차적으로 수행하는 것
- 비직렬(Non-serial) 스케줄 : 인터리빙(Interleaving) 방식을 이용하여 트랜잭션들을 병행하여 수행하는 것
- 직렬 가능(Serializable) 스케줄 : 직렬성을 가진 스케줄. 트랜잭션이 동시에 수행되더라도 직렬 스케줄과 동일한 결과를 갖는 것
트랜잭션 직렬성 = 충돌직렬 가능성 + 뷰 직렬 가능성
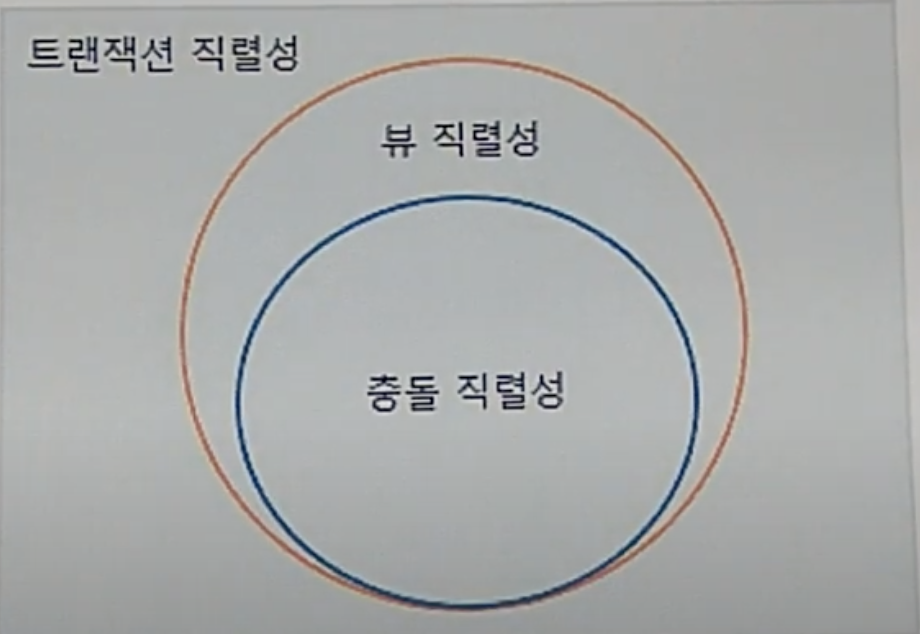
뷰 직렬 가능성 :
세 조건을 만족해야 한다. 밑의 병렬적인 스케쥴을 직렬 적인 스케쥴로 바꾼것이랑 비교해야한다.
그럼 T1이 먼저 read write 하고 T2가 write하고 T3가 write 하는 경우이다.
1) 데이터 x에 대하여 S에서 트랜잭션 Ti가 x의 초깃값을 읽는다면, S'에서도 Ti가 초깃값을 읽어야 한다.
2) S에서 트랜잭션 Ti가 수행한 모든 read(x)의 연산 값이 Tj가 수행한 write(x)가 생성한 값이라면, S'에서 Ti가 수행한 모든 read(x)의 연산 값도 Tj가 수행한 write(x)가 생성한 값이어야 한다.
3) S에서 Ti가 마지막 write(x)를 수행했다면, S'에서도 Ti가 마지막으로 write(x)를 수행해야 한다
즉 밑에 그림에서 T1이 먼저 읽엇는데 직렬도 바꿔도 그렇다 (1번성립), T1,2,3중 누구든지 Read할때 그전에 write한 놈의 실행 순서가 같아야 한다. ex> T1 Write T2 READ이면 직렬로 바꿔도 그래야 함( 2번성립, 그런 경우가 없다 밑에선)
T3가 마지막으로 Write하고 직렬로 바꿔도 T3가 Write한다.

충돌 직렬 가능성 :

왼쪽은 interleaving하고 있고 오른쪽거는 한쪽으로 몰았다.
하지만 이는 결과가 똑같다. 그 이유는 write -> read시 화살표가 그여지는데 이게 사이클이 안 만들어 지면 된다.
A에 대해서 T1이 write를 했는데 이후 T2가 Read했으므로 화살표가 그어진다. 하지만 T2가 Write한 후에 T1이 Read하지 않았으므로 사이클은 형성되지 않는다.
결국은 R-W가 순서대로 트랜잭션마다 일어나면 된다. 만약 여기서 T1뒤쪽에 Write A하면 충돌 직렬하지 않다.


하둡
여러 개의 컴퓨터를 하나로 묶어 대용량 데이터를 처리하는 기술
분산파일시스템(HDFS)와 저장된 분산 파일을 분산된 서버의 cpu와 메모리 자원을 이용하여 빠르게 분석하는 맵리듀스 플랫폼으로 구성



스토리지 종류
DAS(Direct Attached Storage) : 전용 케이블을 이용해 서버와 스토리지를 직접 연결한다. 이해하기 쉽게 일반 사용자들이 많이 쓰는 외장형 하드 방식
장점 1) 가격이 다른 종류에 비해 저렴하다
2) 설치 및 운용이 손쉽다
3) 직접 연결하기에 속도가 빠르다
단점 1) 서버 포트 수에 한계가 있다.
2) 서버가 다운될 경우 해당 서버와 연결되어 있던 스토리지는 모두 사용이 불가능
3) 스토리지가 서버에서 분리되는 경우 저장되어 있던 데이터 손실이 발생할 가능성이 있다.

NAS(Network Attached Storage) : LAN에 연결한다. 내부 사용자 및 외부 사용자들은 NAS에서 데이터를 검색하고 저장한다
중앙 집중식 데이터 저장 방법이다.
장점 1) 포트 수 제한이 거의 없어서 확장성이 좋다
2) 데이터를 중앙 집중화 하기에 좋다
3) 쉬운 접근성과 백업 기능이 있다.
4) 설치 역시 간단하다
단점 1) 사용자가 많아질수록 속도는 현저히 느려진다.
2) 높은 보안 수준을 요구하는 곳에는 적합하지 않다.

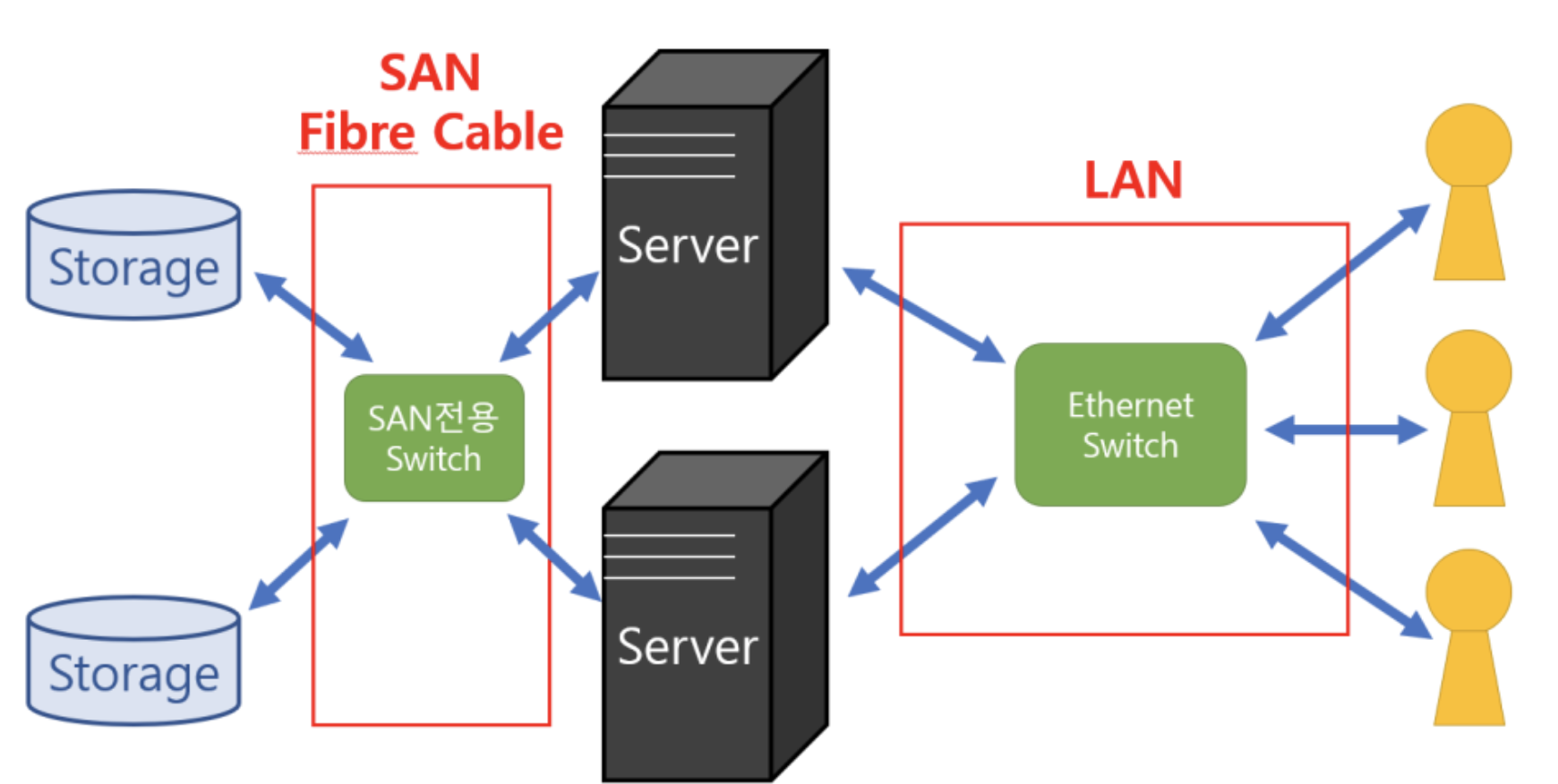
SAN(Storage Area Network) : 블록 스토리지로 이루어진 방식으로 고용량 및 고성능이 요구되는 대규모 네트워크 구성에 적합하다.
장점 1) 이기종 저장장치 간 연결이 가능하다
2) 저장장치 간 데이터 이동이 가능하다.
3) 광 케이블을 이용해 연결하므로 빠르며 전송 거리 또한 길다
4) 다중 사용자 환경에 매우 유용하다.
'Study' 카테고리의 다른 글
| 전산직 정보보호론 정리 (0) | 2021.08.11 |
|---|---|
| 정보보안기사필기 요약 (0) | 2021.08.10 |
| OPTEE pc레지스터 & secure storage(수정중) (0) | 2021.07.26 |
| OPTEE Systemcall Hash연산 (0) | 2021.07.25 |
| ELF파일 (0) | 2021.07.25 |